Polyglot word embeddings obtained by training a skipgram model on a multi-lingual corpus discover extremely high-quality language clusters.
These can be trivially retrieved using an algorithm like $k-$Means giving us a fully unsupervised language identification system.
Experiments show that these clusters are on-par with results produced by popular open source (FastText LangID) and commercial models (Google Cloud Translation).
We have successfully used this technique in many situations involving several low-resource languages that are poorly supported by popular open source models.
This blog post covers methods, intuition, and links to an implementation based on 100-dimensional FastText embeddings.
Background
The skipgram model takes a word as input and predicts its context.
The pipeline maps a one-hot representation of a word in the vocabulary $\mathcal{V}$ to a dense, real-valued vector called a word embedding.
The training scheme for this model involves words and the contexts they appear in (the positives), and negative examples obtained using negative sampling.
We’ll henceforth concern ourselves with 100-dimensional FastText word embeddings and refer to them as FastText-100. These results are consistent with the 300-dimensional variant as well.
A document embedding is a single real-valued vector for a full document (sentence, paragraph, social media post etc.).
There are several popular ways of obtaining these but we’ll just use the FastText default:
- obtain the word-vectors for all words in the document,
- normalize them, and
- average them to obtain a single 100-dimensional vector for the whole document.
Polyglot Embeddings
I am going to use a pre-processed Europarl corpus sourced from here.
After a preprocessing step:
- The text is lowercased and punctuation stripped.
- Each line corresponds to a distinct document, and
- The full corpus is shuffled.
The corpus contains 21 languages. The documents are shuffled and (polyglot) FastText-100 embeddings are trained on this 21-language corpus.
You can download it (and models and everything) here
We can visualize the document embedding space using a TSNE plot:
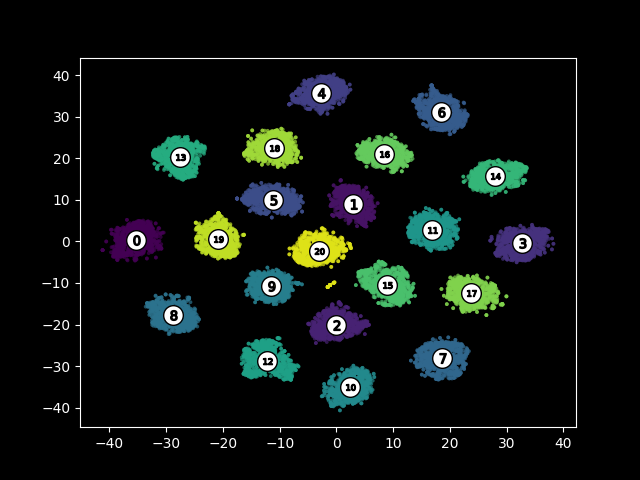
We observe 21 clear, well defined clusters.
Manual inspection shows that there is exactly one cluster per language in the corpus.
A simple clustering algorithm like $k-$Means is able to retrieve these clusters and on inspection we notice that the corpus is split into 21 parts - each containing documents written in exactly one language.
A Language Identification System
There are two undiscussed steps - picking a value of $k$, and assigning a language to one of these language clusters.
The latter is easy to solve - human annotators assign the dominant language in each cluster as that cluster’s language. A subsequent cluster membership test can be used for a test document.
What remains to be discussed is picking a good $k$ value for the $k$-Means algorithm.
In our experience, popular methods like the silhouette heuristic, or the elbow method are quite capable of producing a reasonable value for $k$.
For the Europarl corpus above, here is a silhouette plot for $k=21$:
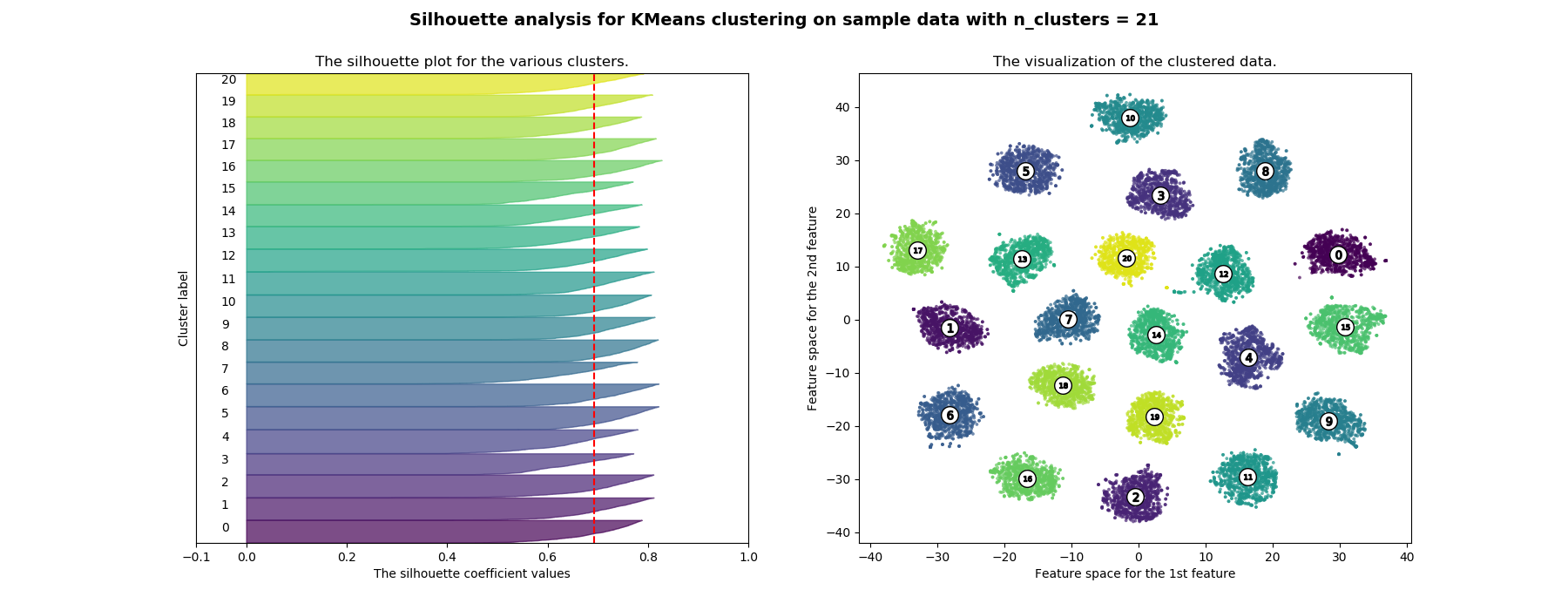
And here is the elbow plot:
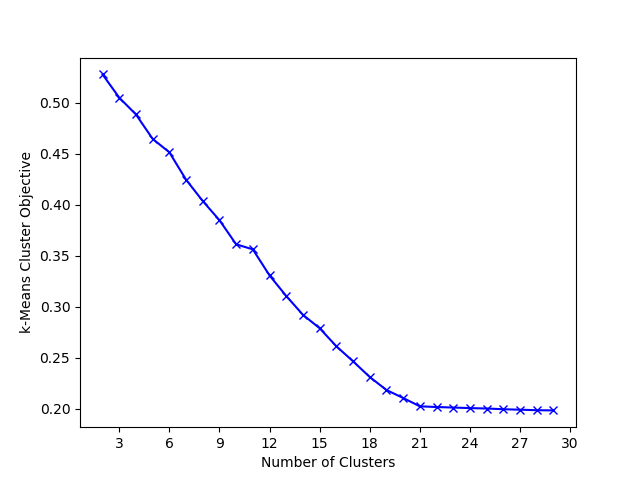
In both cases, we see 21 as the optimal number of clusters for this corpus.
How Good Are These Clusters?
We run human evaluations on several corpora and report performance against popular open and commercial models. These corpora contain several low-resource languages and thus popular language identification systems are unable to identify them at times:
- $\mathcal{D}_{IndPak}$ - Indian and Pakistani News Channels - Contains English, Romanized and Devanagiri Hindi.
- $\mathcal{D}_{ABP}$ - Bengali News Network - English, Romanized Hindi, Romanized and native script Bengali.
- $\mathcal{D}_{OTV}$ - Oriya News Network - English, Romanized Hindi, Romanized and native script Oriya.
In all these cases, our model is able to perform exceptionally well. In cases where it makes sense, performance is on par with popular and commercial models. For full details see our paper.
I’m attached the embedding space from $\mathcal{D}_{IndPak}$ here:
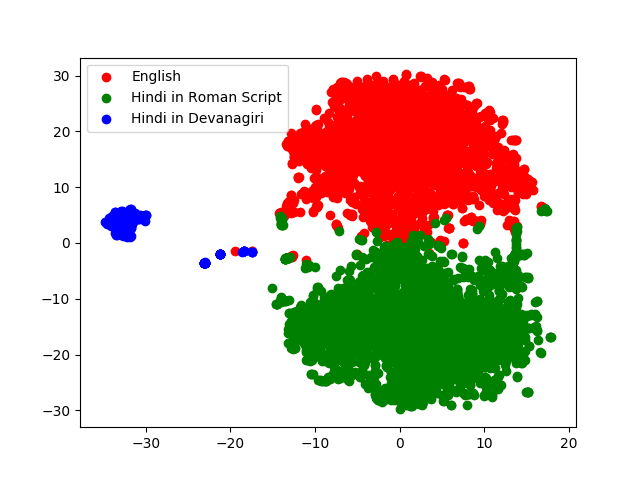
Notice how clean the full embedding space is.
Intuition
Why is this happening?
The skipgram training scheme predicts a context for an input word.
A Hindi word’s context is likely to consist of other Hindi words; and example contexts retrieved in the negative sampling phase are likely to be written in languages distinct from the language of the input word.
It just so happens that the skipgram training scheme is perfectly designed to separate out a multilingual corpus into its monolingual components.
And the embeddings reflect this - as we can see from the TSNE plots above.
Note that inside the embedding subspace corresponding to a language, we observe similar properties typically observed when these word embeddings are trained on monolingual corpora.
i.e. standard stuff like analogies, semantic similarities etc. work very well.
In The Wild
We have used this technique in a variety of text analyses centered in South and South-East Asia.
In particular, South Asian social media users used Romanized variants of their native languages that are mostly unsupported by popular language identification systems.
This unsupervised method is highly capable in such situations eliminating significant annotation requirements.
In this paper analyzing the Rohingya crisis, from among dozens of languages (many low-resource), this technique was utilized to extract out English social media posts.
In an analysis of the India-Pakistan crisis of 2019, this technique was used to separate out Romanized Hindi and English for further analysis.
In soon to be published work analyzing the 2019 Indian election, nearly a dozen Indian regional languages were extracted and analyzed with zero annotation burden.
In almost all these cases existing solutions performed poorly or involved prohibitive costs.
For linguistically diverse regions, we foresee that polyglot embeddings are going to be an important NLP pipeline component.
In Related News
Unsupervised or low-supervision methods have been increasingly deployed in multlingual settings.
For instance, embeddings learned by machine translation models seem to be organized along linguistic lines.
A clever training setup was used for unsupervised machine translation in this paper.
Polyglot embeddings (contextual or otherwise) have been used for performance gains in several tasks.
Links
Cite
@inproceedings{kashmir,
title={Hope Speech Detection: A Computational Analysis of the Voice of Peace},
author={Palakodety, Shriphani and KhudaBukhsh, Ashiqur R. and Carbonell, Jaime G},
booktitle={Proceedings of ECAI 2020},
pages={To appear},
year={2020}
}