Watch Date Change Mechanism
Someone on r/watches posted this image of a date-change mechanism that illustrates why you shouldn’t change the date close to midnight:




Someone on r/watches posted this image of a date-change mechanism that illustrates why you shouldn’t change the date close to midnight:
Singapore’s government (and Mentos was involved in this awkward project) used this ad on their National Day celebrations to encourage people to copulate and increase Singapore’s birth rate. I hypothesized that a low fertility rate (number of children per woman) was not unique to Singapore (though the problem might be more acute in Singapore).
Here’s a plot of GDP vs. fertility rates for all nations. The red dots are the devloped countries:
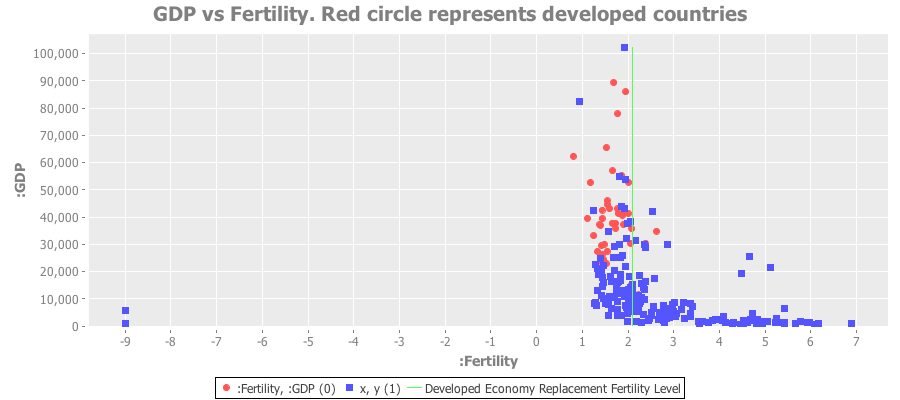
Clearly the poorest nations have a ridiculously high fertility rate. The red dots represent the developed economies - almost all of which lie below the replacement fertility rate of 2.1
Here’s a plot of just the developed economies:
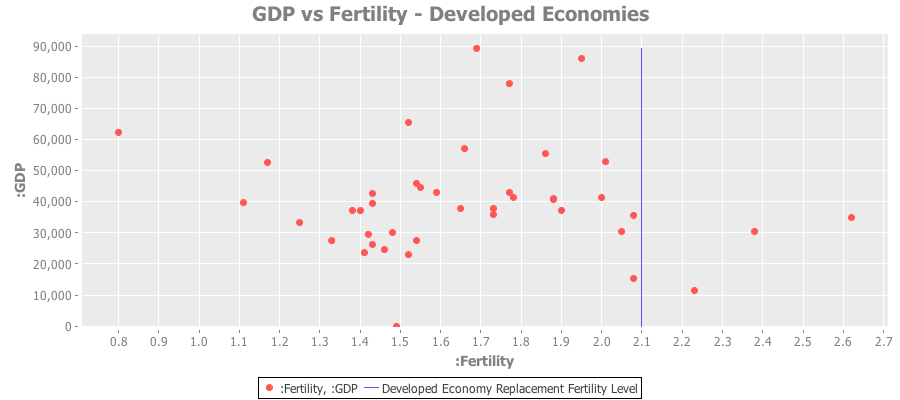
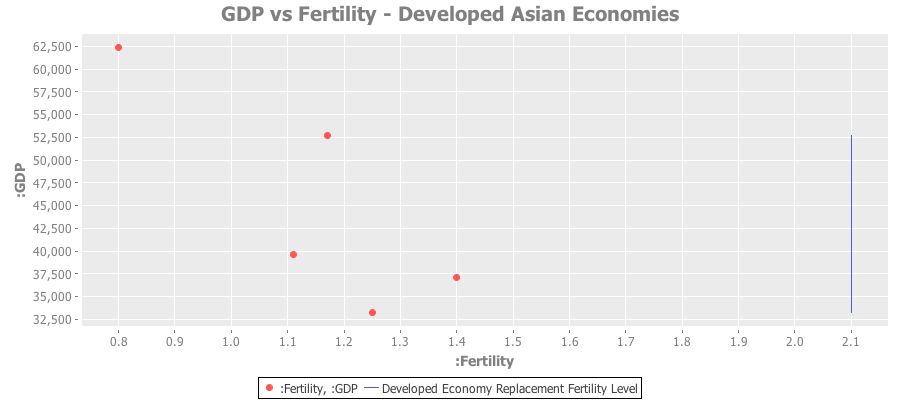
And a similar plot for developed Asian economies:
Full source code and datasets available in this github repo.
Java’s string trim routine tests for whitespace using Character.isWhitespace and so does Clojure’s clojure.string/trim.
While processing a dataset off the web containing unicode space characters, the trim routine failed to do anything useful. Luckily, a StackOverflow thread suggested using a routine from Google’s guava library. So in Clojure, you can do this:
1 |
(.trimFrom CharMatcher/WHITESPACE %) |
and this will do the job.
I found this recent paper on adhoc-IR from CIKM 2013. I haven’t worked in this area but the results seem promising. Essentially, instead of TF, you store an indegree count. The graph in question is the term co-occurrence graph within a window with the direction indicating word-order. The paper won hon. mention at the CIKM so it is clearly very cool.
This is a post I wrote to teach myself about Heritrix and modifying it. There are solid motivations for modifying web-crawlers (say we know how to beat a simple BFS for some specific website). In this post, I will modify a routine that is central to web-crawling - extracting URLs from a webpage.
Back when Blekko had an API, I threw this implementation of their API together for a small project I was working on. You can only query blekko with this (the API allows slashtag manipulation and all that which I didn’t bother with).
Anyway, you can do this:
With leiningen:
[clj_blekko "0.1.0"]With maven:
<dependency>
<groupId>clj_blekko</groupId>
<artifactId>clj_blekko</artifactId>
<version>0.1.0</version>
</dependency>You can just do this:
user> (use 'clj-blekko.core :reload)
user> (clojure.pprint/pprint (:RESULT (run-query "shriphani" api-key :json true :page 2)))
[{:c 1,
:display_url
"kindle.amazon.com/profile/Werner-Vogels/160/followers/65",
:n_group 41,
:short_host "kindle.amazon.com",
:short_host_url "http://kindle.amazon.com/",
:snippet
"1 Followers 0 Books with Public Notes. Peter van der Reijden. 5 Followers 0 Books with Public Notes. 4 Followers 0 Books with Public Notes. 0 Followers 0 Books with Public Notes.",
:url
"https://kindle.amazon.com/profile/Werner-Vogels/160/followers/65",
:url_title "Amazon Kindle - Werner Vogels - Followers"}
{:c 2,
:display_url "yelp.com/biz/M8P96GmGImU0KOrFMfVCKw",
:n_group 42,
:short_host "yelp.com",
:short_host_url "http://www.yelp.com/",
:snippet
"33 reviews for Blue Nile Restaurant. Blue Nile Restaurant. 117 Northwestern Ave Ste 2 West Lafayette, IN 47906. Mon-Sat 11 am - 11 pm. Sun 12 pm - 10 pm.",
:url "http://www.yelp.com/biz/M8P96GmGImU0KOrFMfVCKw",
:url_title
"<strong>Yelp.com</strong> - Blue Nile Restaurant - West Lafayette, IN"}
{:c 3,
:display_url "yelp.com/biz/blue-ni
le-restaurant-west-lafayette",
:n_group 43,
:short_host "yelp.com",
:short_host_url "http://www.yelp.com/",
:snippet
"34 reviews for Blue Nile Restaurant. Blue Nile Restaurant. 117 Northwestern Ave Ste 2 West Lafayette, IN 47906. Mon-Sat 11 am - 11 pm. Sun 12 pm - 10 pm.",
:url "http://www.yelp.com/biz/blue-nile-restaurant-west-lafayette",
:url_title
"<strong>Yelp.com</strong> - Blue Nile Restaurant - West Lafayette, IN"}
{:c 4,
:display_url "amazon.com/gp/product/0679776222?link_code=as3",
:n_group 44,
:short_host "amazon.com",
:short_host_url "http://www.amazon.com/",
:snippet
"Frequently Bought Together. Customers Who Bought This Item Also Bought. More About the Authors. Very Bad Poetry Paperback. Very Bad Poetry (Vintage) and over one million other books are available for Amazon Kindle.",
:url "http://www.amazon.com/gp/product/0679776222?link_code=as3",
:url_title
"<strong>Amazon.com</strong> - Very Bad Poetry - Ross Petras, Kathryn Petras - 9780679776222 - Amazo
n.com - Books"}
{:c 5,
:display_url "yelp.com/biz/shaukin-indian-fast-food-west-lafayette",
:n_group 45,
:short_host "yelp.com",
:short_host_url "http://www.yelp.com/",
:snippet
"23 reviews for Shaukin Indian Fast Food. 138 S River Rd West Lafayette, IN 47906. Tue-Thu 4 pm - 10 pm. Fri-Sun 12 pm - 10 pm. Good for Kids.",
:url
"http://www.yelp.com/biz/shaukin-indian-fast-food-west-lafayette",
:url_title
"<strong>Yelp.com</strong> - Shaukin Indian Fast Food - West Lafayette, IN"}
{:c 6,
:display_url
"reddit.com/.../who_here_doesnt_sympathize_with_g20_rioters",
:n_group 46,
:short_host "reddit.com",
:short_host_url "http://www.reddit.com/",
:snippet
"Login or register in seconds. Limit my search to /r/worldnews. Use the following search parameters to narrow your results. Search for "text" in url. Search for "text" in self post contents.",
:url
"http://www.reddit.com/r/worldnews/comments/cjhse/who_here_doesnt_sympathize_with_g20_rioters/",
:url_title
"<strong>Too Many Requests</strong> - Who here doesn't sympathize with G20 rioters destroying people's property - worldnews"}
{:c 7,
:display_url "yelp.ie/biz/shaukin-indian-fast-food-west-lafayette",
:n_group 47,
:short_host "yelp.ie",
:short_host_url "http://www.yelp.ie/",
:snippet
"Recommended Reviews for Shaukin Indian Fast Food. Cookies help us deliver our services. By using our services, you agree to our use of cookies. 138 S River Rd West Lafayette, IN 47906. Good for Children.",
:url
"http://www.yelp.ie/biz/shaukin-indian-fast-food-west-lafayette",
:url_title "Shaukin Indian Fast Food - West Lafayette, IN"}
{:c 8,
:display_url
"en.yelp.be/biz/shaukin-indian-fast-food-west-lafayette",
:n_group 48,
:short_host "en.yelp.be",
:short_host_url "http://en.yelp.be/",
:snippet
"25 reviews for Shaukin Indian Fast Food. 138 S River Rd West Lafayette, IN 47906. Good for Children. Accepts Credit Cards. Good for Groups.",
:url "http://en.yelp.be/biz/shaukin-ind
ian-fast-food-west-lafayette",
:url_title "Shaukin Indian Fast Food - West Lafayette, IN"}
{:c 9,
:display_url "quora.com/Colin-Ho",
:n_group 49,
:short_host "quora.com",
:short_host_url "http://www.quora.com/",
:snippet
"You must sign in to read Quora past the first answer. Login to Quora. Complete your account on Quora. There are some updates to this page that haven't been applied yet because you've entered some data into a form. Refresh this page to receive new updates.",
:url "http://www.quora.com/Colin-Ho",
:url_title "Colin Ho - <strong>Quora</strong>"}
{:c 10,
:display_url
"quora.com/...change-the-world-the-most-within-the-next-25-years",
:n_group 50,
:short_host "quora.com",
:short_host_url "http://www.quora.com/",
:snippet
"You must sign in to read past the first answer. Complete Your Profile. Login to Quora. You must sign in to read all of Quora. You must be signed in to read this answer.",
:url
"http://www.quora.com/Which-technological-innovatio
n-will-change-the-world-the-most-within-the-next-25-years",
:url_title
"<strong>Quora</strong> - Which technological innovation will change the world the most within the next 25 years - Quora"}
{:display_url "meetup.com/Clojure-PGH",
:short_host "meetup.com",
:c 11,
:url_title
"<strong>Meetup</strong> - Pittsburgh Clojure Users Group (Pittsburgh, PA) - Meetup",
:n_group 51,
:doc_date "Mar 2010",
:url "http://www.meetup.com/Clojure-PGH/",
:short_host_url "http://www.meetup.com/",
:snippet
"Welcome old lispers and new schemers. Come to our next event to meet other programmers interested in the latest secret alien technology. We are building a community of people who want to learn from and teach others about Clojure. Talking with printed notes is encouraged, powerpoints are forbidden.",
:doc_date_iso "2010-03-04 00:00:00"}
{:c 12,
:display_url
"quora.com/.../How-do-you-ensure-that-TAs-for-introductory-CS...",
:n_group 52,
:short_host "quora.com",
:short_host_url "http://w
ww.quora.com/",
:snippet
"You must sign in to read past the first answer. Complete Your Profile. Login to Quora. You must sign in to read all of Quora. You must be signed in to read this answer.",
:url
"http://www.quora.com/Computer-Science-Education/How-do-you-ensure-that-TAs-for-introductory-CS-classes-teach-at-a-high-quality",
:url_title
"<strong>Quora</strong> - Computer Science Education - How do you ensure that TAs for introductory CS classes teach at ... "}
{:c 13,
:display_url
"quora.com/.../Is-it-already-too-late-to-get-on-the-wave-of-f...",
:n_group 53,
:short_host "quora.com",
:short_host_url "http://www.quora.com/",
:snippet
"If I were to start learning Scala and the functional programming paradigm (coming from imperative languages), am I getting early or late to the party. I'm a functional learner myself.",
:url
"http://www.quora.com/Scala/Is-it-already-too-late-to-get-on-the-wave-of-functional-programming-and-Scala",
:url_title
"<strong>Quora</strong>
- Is it already too late to get on the wave of functional programming and Scala"}
{:c 14,
:display_url "python.org/doc/3.0.1/about.html",
:n_group 54,
:short_host "python.org",
:short_host_url "http://www.python.org/",
:snippet
"Contributors to the Python Documentation. About these documents. These documents are generated from reStructuredText sources by Sphinx, a document processor specifically written for the Python documentation.",
:url "http://www.python.org/doc/3.0.1/about.html",
:url_title
"<strong>Python Programming Language</strong> - About these documents — Python v3.0.1 documentation"}]Anyway, thought it might be useful (even though blekko’s gone and nuked free access to their API).
Earlier this week I gave a talk on scraping with clojure - primarily using clj-xpath and enlive at the Pittsburgh clojure meetup group. Slides and code are linked to below.
Code: https://github.com/shriphani/clojure_scraping_overview
I can clearly recall why I became a computer scientist. I was sitting in a class and we were discussing how cons was implemented. And then I saw this definition:
1 2 3 4 5 6 7 8 9 |
The lambda calculus and the material in the little schemer kept me in the field (computer-science i.e.) and assured me that there would never be a dearth of aha! moments in my education.
Good educators can deliver such aha! moments in every single lecture. A good textbook can do it several times each chapter.
I have since tried to find material that delivers such aha! moments.
Hopefully, I will encounter them for the rest of my life in whatever I do.
The Vatican has a fantastic interactive view of Michelangelo’s work in the Sistine Chapel.

I recently spent some time working on a simple linear algebra problem - decompose a matrix $ M $ into a low-rank component $ L $ and a sparse component $ S $. The algorithm I used was very trivial to implement (and parallelize using map-reduce).
In this post, I will implement this very simple algorithm, explain the objective function and demonstrate its (amazing) effectiveness on a surveillance-camera dataset.
Twitter: @shriphani
Instagram: @life_of_ess
Fortior Per Mentem
(c) Shriphani Palakodety 2013-2020